Practical aspects of random-wound machines
Hi y’all.
Here’s the third and for-now final post popularizing my latest journal article. If you’ve somehow forgotten, it’s about modelling circulating current losses in random-wound machines. In my previous two posts, I introduced some basic terminology necessary for understanding, well, anything about the topic, and began to describe the analysis methods I utilized and developed. So, if you haven’t checked those two out yet, now would be a good time.
So, let’s move on. Today, I’m going to tell you about the method that finally turned out to work quite nicely, and muse about some practical implications of my work, and how to continue it in the future.
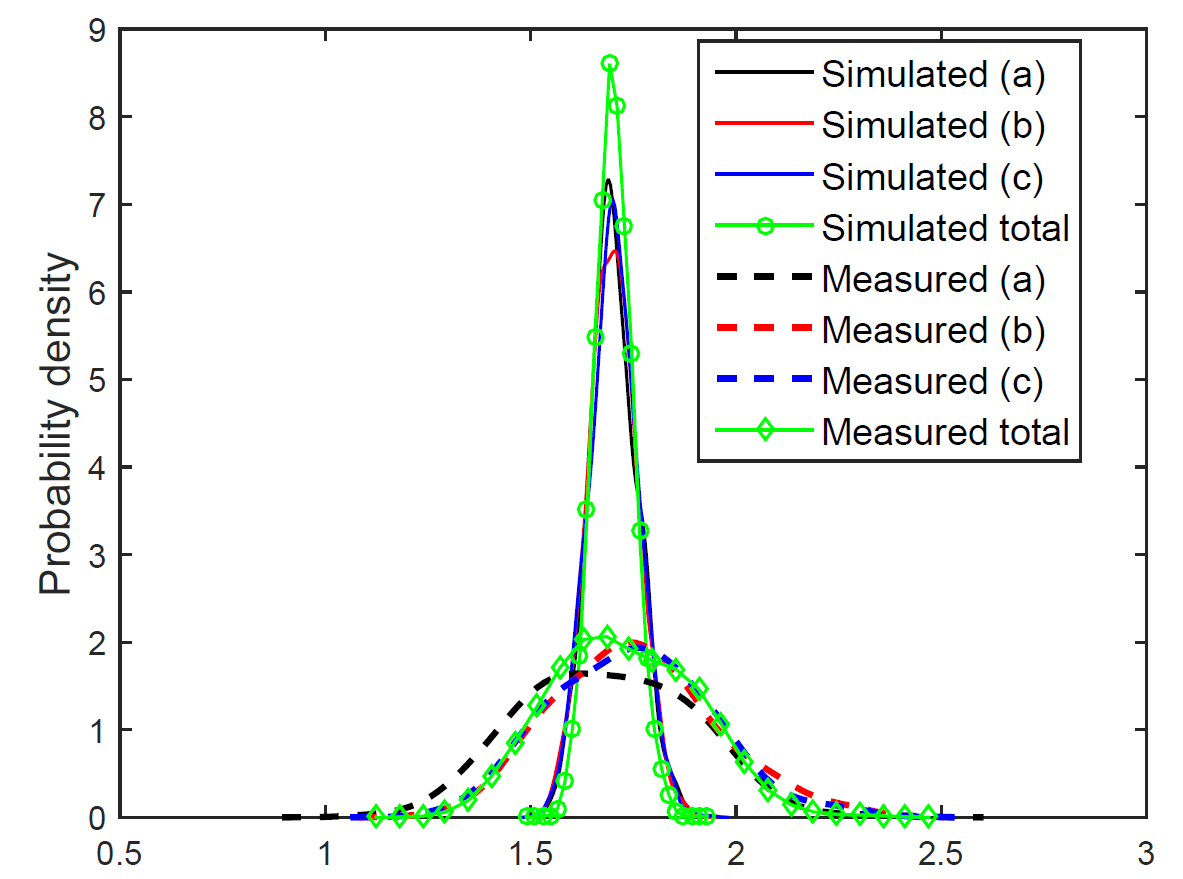
As you remember from my previous post, I first tried to model the uncertainty in the random windings with random permutations. And as you definitely should remember (I certainly do), it didn’t work out awfully well. The results were of the correct magnitude, yes, but had a far too narrow distribution compared to the measurement data we had. I’ve again included a figure of the results below, so you don’t have to flip between the previous post and this.
Improved results
Funnily enough, I was able to get much better results with a single trick. In my first approach, I used independent random permutations – I assumed that the strand positions in any slot were not influenced by the ones in the next. After banging my head against the wall until my ears started bleeding a brief moment of consideration, I started to wonder if this really was the case.
Indeed, it started to look more and more reasonable to me that the strands did not have any universal default positions per se. Instead, the most likely position would probably be the same as in the previous slot. In a way, any position that any strand happens to end up in slot 1, would become the default position also for slot 2, and so on.
Thus, I changed my sampling algorithm to reflect this assumption, and that’s when the magic happened. Look and behold the results below!
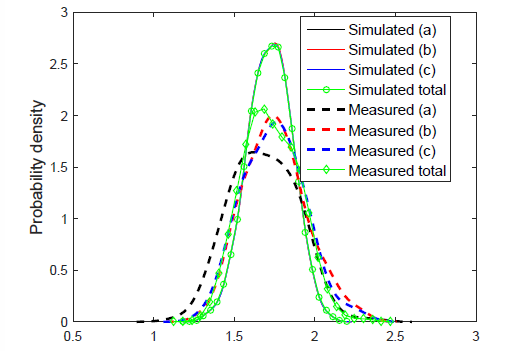
As you see, the simulated results are now much closer to the measured ones. Of course, there’s still plenty of room for improvement, but they’re still quite nice enough to actually be of some use.
Practical considerations
And what would that actual use be? Well, let’s have an electric car – the motor of which to be precise – as an example.
Being able to model losses is the first requirement for properly limiting and reducing them. And reducing the losses obviously means improving the efficiency. Energy efficiency is a huge topic nowadays, with all the environmental considerations, new EU standards, and whatnot.
And that’s for a good reason. Electrical machines consume a lion’s share of the electricity produced world-wide, so even a minor efficiency boost will have a huge combined effect both on harmful emissions and on the monetary side as well, i.e. money spent on electricity bills.
Efficiency is boring
But, in an electric vehicle efficiency is not such a huge deal. The machines inside are already quite efficient, much more so than gasoline engines. So, improving the efficiency from 90 percent to 95 percent will not have a very large effect on the charging costs. The range of the vehicle won’t be much better, either.
However, this is not to say that we could stop looking at losses altogether. Far from it, in fact.
Excellence is NOT boring
Losses mean heat.
And that heat, it has to go somewhere. And in an electric car, a cooling system is needed for the heat to go anywhere fast enough. Otherwise we’d be stuck with a very large motor of a low power density. That means the bulky and ugly utilitarian industry motor you see driving a rusty pump or whatever. Don’t get me wrong, those workhorses do fulfill a very important purpose. I only mean that this purpose is not propelling a car.
But I digress. So a cooling system is needed. And the more losses the motor has, the larger and more powerful that system has to be. And that costs money, takes space, and gives us more potential parts to break down.
So, reduce the losses, reduce the size of the cooling system, reduce the size of the motor. All-around win.
Moar strain
Also, the motors of electric vehicles are often subjected to huge temporary overloads – think a highway overtake, or street racing from the traffic light stop. The overload powers can be so large that the cooling system has no realistic hope of coping them. Instead, the motor starts to heat up rapidly, at a rate determined almost purely by its heat capacity.
And under these conditions, the losses of the machine do make a huge difference. Remember the efficiency improvement from 90 to 95 percent that I brought up as an example? Despite having only a minor effect on the vehicle range, it could as much as double its capacity for longer and more frequent bouts of heavy acceleration. Or put the other way round, the same peak power capacity could be realized with a smaller motor, yielding savings in mass and cost.
(Now of course, peak power is also limited by other factors beside the losses, but they still play an important role.)
So, even things looking really minor on the first glance can turn out to be quite significant. Sound familiar?
And that, dear readers, concludes my first attempt at bringing my own research a bit closer to somebody who is not me. Like it or hate it – hit me a comment!
P.S.
After submitting the article, I got an idea for a different randomization algorithm for the strands. Right now, it’s scribbled down on the computer-code-equivalent of the corner of an A4 sheet, but it seems to work better still than the one I presented here. I hope to be able to get back to it during the course of the summer, and publish the results in some suitable forum afterward. Take that with a large grain of salt though – in my experience testing out new research ideas has a relatively depressing hit-miss ratio. But, I’ll remain optimistic as ever.
UPDATE: The new algorithm is slowly finding its way to a paper!
-Antti
Check out EMDtool - Electric Motor Design toolbox for Matlab.
Need help with electric motor design or design software? Let's get in touch - satisfaction guaranteed!