How to analyse a random winding
In my previous post, I introduced to you my latest journal article, and briefly explained the concepts of a random-wound machine and circulating currents. So, if you have yet to read that, I suggest you do it now.
What I forgot to mention was that inside the machine, the strands are located in slots – depressions in the stator iron core of the machine. Despite all the uncertainties in machine manufacture, we do pretty much know in which slot each strand ends up.
Random winding
Now that we have that out of the way, let’s move on.
Last time, we concluded that the circulating currents and the associated losses are highly stochastic or statistical in nature. This phenomenon is due to the uncertain positions of the strands inside the slots, and compounded by their large number. This uncertainty makes the losses very difficult to analyse, and they have thus received relatively little scientific attention. (By the way, click here to read more about uncertainty in engineering.)
Until now. My analysis is based on a two-pronged approach.
Fixing a set of positions
First, I generated a pre-defined set of strand positions inside each slot of the machine. In other words, each strand would be assigned to one of these bins, and nowhere else. This, obviously, simplifies the analysis tremendously, compared to allowing the strands to float freely. Indeed, this would require considering all possible strand packings inside each slot.
Nevertheless, this should still allow us to approximate the actual physical phenomenon – currents and losses – to a sufficient accuracy. As to why exactly this is the case, see Appendix B in my article.
Permuting the positions
Secondly – to actually model to uncertainty – the strands were randomly permuted between these bins. In other words, each strand would still get assigned to one bin (and each bin would get its own strand). But the order would change – which strand goes into which bin. The statistical properties were then analysed with the well-known Monte Carlo method.
Now, in an actual machine, the strand positions are of course not completely random, meaning they are not uniformly permuted between the figurative bins. Indeed, this would result in an awful tangle of copper wires, and nobody in their right mind would buy the machine in question after seeing it. Instead, the deviations in strand positions from slot to slot are probably quite smooth.
That first situation – the tangled one – would have corresponded to uniformly distributed random permutations. These would have been easy to generate, but alas wouldn’t have corresponded to the actual physical situation. So, I had to come up with something else.
Sampling algorithm
So, I devised with a sampling algorithm, probably enough to make any mathematician bleed out their eyeballs if not spontaneously combust. It generates permutations that are approximately normally distributed, meaning each strand is most likely assigned to its default position, with the probability decaying with the distance of each bin from the default one. I hypothesized this would be a sufficient approximation of the underlying physical process.
First results
Unfortunately, it turned out it wasn’t. Indeed, the figure below shows the probability densities of the simulated loss factors, along with the ones obtained with my algorithm.
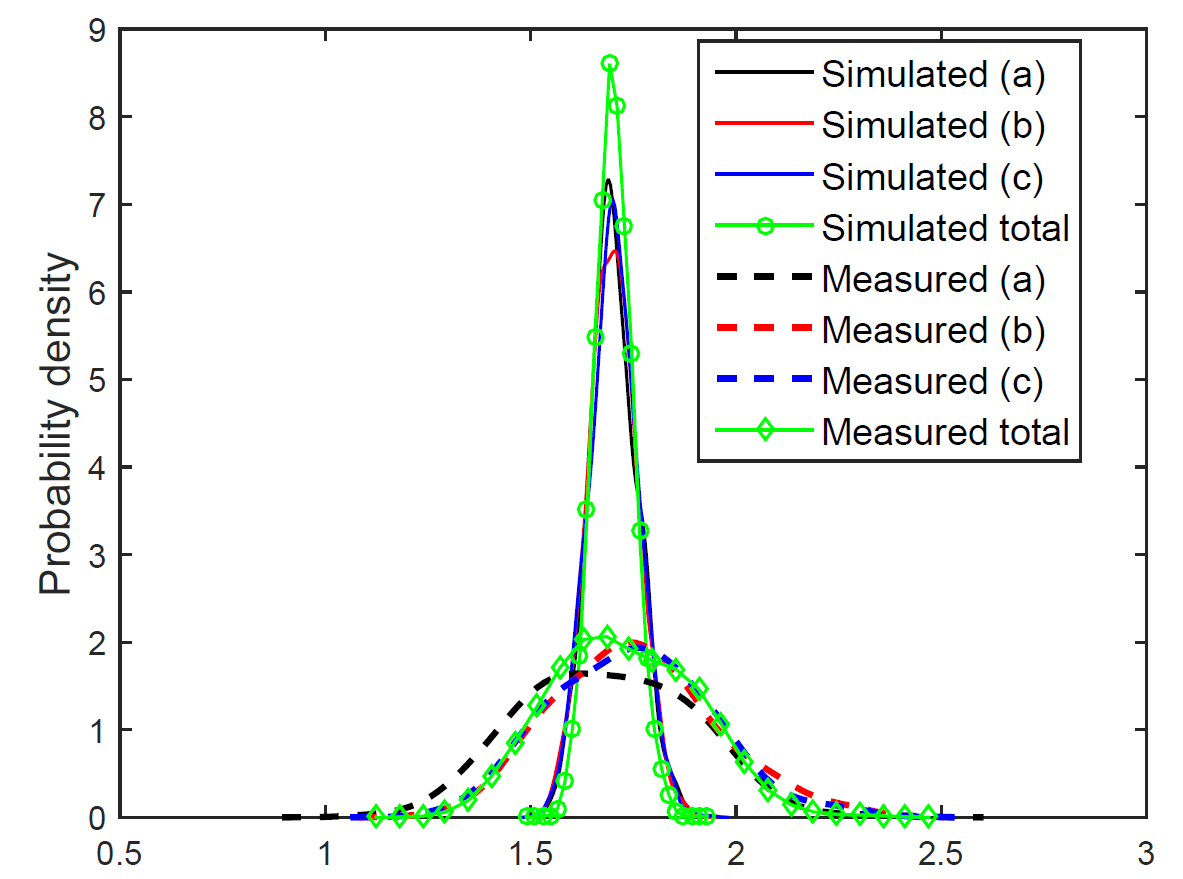
Obviously, the results are not very good. The mean values agree relatively well, but the simulated results are far too narrowly distributed compared to the measured ones.
And I did play with different sampling algorithms and more detailed models quite a bit, but was not able to obtain anything better. To accomplish that, I needed to change some of my assumptions.
Read the next post to learn more!
-Antti
Check out EMDtool - Electric Motor Design toolbox for Matlab.
Need help with electric motor design or design software? Let's get in touch - satisfaction guaranteed!